



Dieser Artikel beleuchtet die Bedeutung von Entitäten in der SEO-Welt und wie Google sie nutzt, um die Qualität der Suchergebnisse zu verbessern. Von der Definition einer Entität bis hin zu ihrer Rolle im Google Knowledge Graph werden die vielfältigen Auswirkungen auf SEO-Strategien untersucht und wie Entitäten dabei helfen können, Inhalte präziser und nutzerfreundlicher zu gestalten.
Das Wichtigste in Kürze
- Entitäten in SEO: Entitäten sind einzigartige Konzepte oder Objekte, die Google nutzt, um Inhalte und deren Beziehungen zu verstehen.
- Bedeutung für Google: Der Knowledge Graph von Google basiert auf Entitäten, um Mehrdeutigkeiten aufzulösen und Synonyme zu verknüpfen.
- Relevanz für SEO: Eine effektive SEO-Strategie sollte die Identifizierung und klare Darstellung von Entitäten berücksichtigen.
- Technologien für Entitäten-Erkennung: Fortschrittliche Technologien wie BERT und MUM helfen Google, Entitäten in verschiedenen Formaten zu erkennen.
Inhalt
Was ist eine Entität?
Die Definition einer Entität ist nicht so einfach und vielleicht müssen wir den Begriff in Bezug auf SEO etwas weniger dogmatisch verwenden.
Wikipedia beschreibt den Begriff Entität wie folgt
„Zum einen bezeichnet er etwas, das existiert, ein Seiendes, einen konkreten oder abstrakten Gegenstand. In diesem Sinn wird der Begriff der Entität in der Regel als Sammelbegriff verwendet, um so unterschiedliche Gegenstände wie Dinge, Eigenschaften, Relationen, Sachverhalte oder Ereignisse auf einmal anzusprechen. Dies ist die im zeitgenössischen Sprachgebrauch gängige Verwendung.„
Wikipedia
Googles Definition einer Entität lautet so:
„A thing or concept that is singular, unique, well-defined, and distinguishable.„
Zusammenfassend kann gesagt werden, dass es sich um ein einzigartiges „Ding“ oder „Konzept“ handeln muss.
Einfacher ist es, den Begriff Entität als Eintrag in einer (Wissens-)Datenbank zu verstehen. Zum Beispiel Wikipedia oder der Google Knowledge Graph. Auch in Datenbanken geht es um die Eindeutigkeit von Einträgen.
Mit dem Knowledge Graph verfügt Google über eine riesige Wissensdatenbank, die mit Entitäten gefüllt ist. Das Besondere am Knowledge Graph ist, dass nicht nur die Entitäten, sondern auch deren Attribute und Beziehungen zu anderen Entitäten enthalten sind.
Es sind die Attribute und Beziehungen, die Entitäten so wertvoll machen. Sie machen mehrdeutige Begriffe eindeutig.
Das Homonym Puma beispielsweise kann sowohl eine Tier als auch ein Unternehmen sein. Beide haben aber unterschiedliche Eigenschaften:
| Puma (Tier) | Puma (Unternehmen) | |
|---|---|---|
| Eigenschaft 1 | Höhe: 60 – 90 cm | Gründer: Rudolf Dassler |
| Eigenschaft 2 | Geschwindigkeit: 64 – 80 km/h | Gründung: 1948 |
| Eigenschaft N | Länge: 2,4 m | Hauptsitz: Herzogenaurach |
| Entitätstyp | Thing | Organization |
Schon mit wenigen Attributen für einen Begriff wird das Prinzip deutlich: Die Eigenschaften eines Begriffs machen ihn einzigartig.
Umgekehrt funktioniert es wie beim Gesellschaftsspiel Tabu: Ein gesuchter Begriff kann so lange anhand seiner Eigenschaften beschrieben werden, bis klar ist, welcher Begriff gemeint ist.
Der Begriff selbst spielt dabei keine große Rolle. Im Knowledge Graph speichert Google die Entitäten in Form einer ID. Für Duplo (das Spielzeug) verwendet Google die ID kg:/m/03vxc_.
Dies gewährleistet nicht nur die Eindeutigkeit, sondern macht die Einträge auch sprachunabhängig.
Dieses Prinzip ist aber nicht nur bei Homonymen sinnvoll. Auch bei Synonymen können Entitäten hilfreich sein. So kann für verschiedene synonyme Begriffe auf die gleiche Entität zurückgegriffen werden.
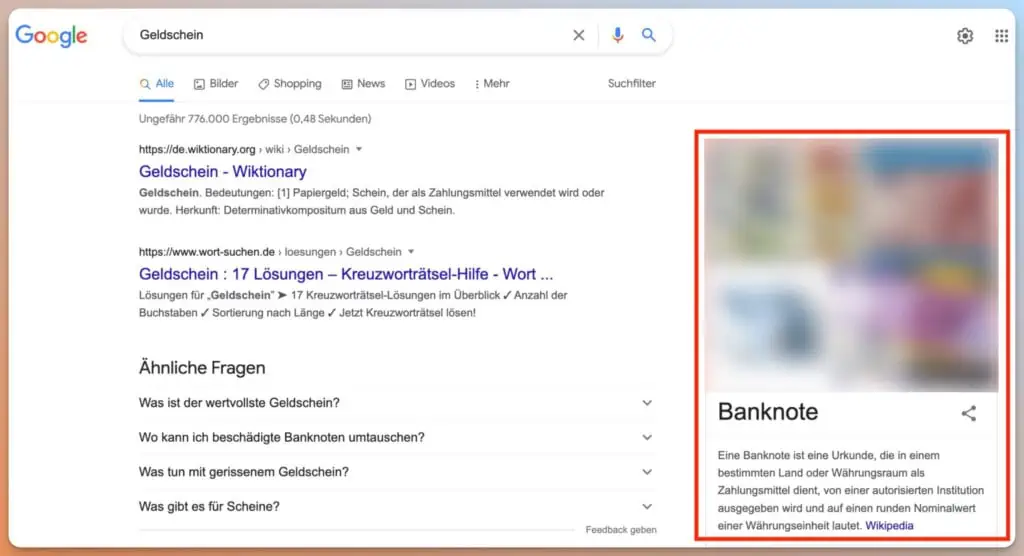
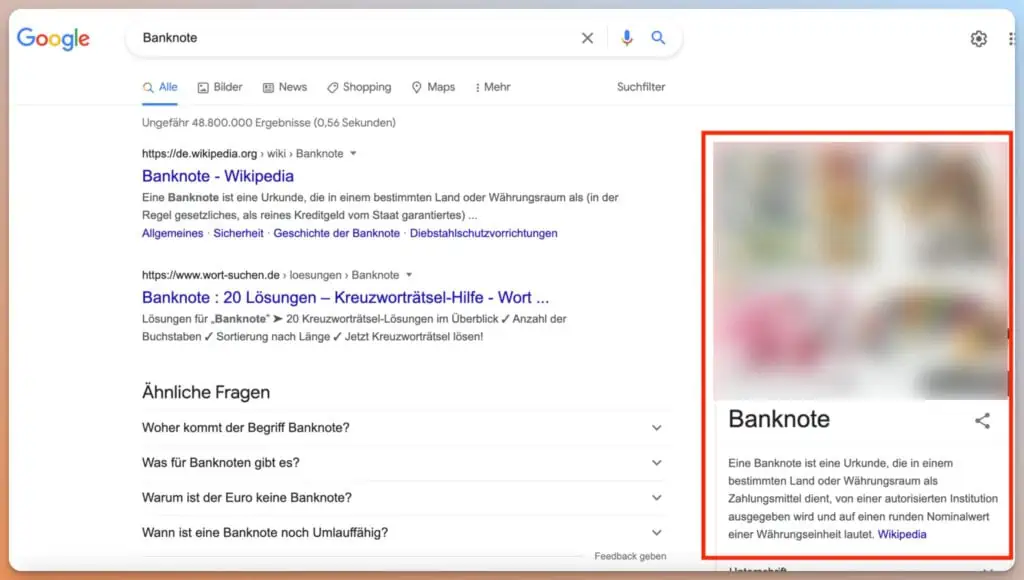
Dies zeigt sich auch im Knowledge Panel der Google-Suche. Hier wird für den Begriff Geldschein der gleiche Eintrag aus dem Knowledge Graph angezeigt wie für den Suchbegriff Banknote:
Benannte Entitäten und Konzepte
Wie bereits erwähnt, wird bei der Definition von Entitäten zwischen „Dingen“ und „Konzepten“ unterschieden.
Benannte Entitäten (Named Entities) können relativ genau bestimmt werden. Es handelt sich immer um eindeutig identifizierbare Objekte wie Firmen, Orte oder Personen.
Konzepte sind schwieriger zu identifizieren. Es handelt sich um abstrakte Dinge wie Zustände, eine Idee oder eine Theorie. Entscheidend ist, dass sie eindeutig sind. Die Eindeutigkeit ergibt sich nicht aus dem Namen der Entität, sondern aus den Eigenschaften (siehe Puma-Beispiel).

Du willst SEO lernen und verständlich erklärt bekommen?
Website-Potentiale erkennen, Keywords recherchieren, SEO-Texte schreiben: Wir zeigen Marketing-Abteilungen, wie sie ihre Websites systematisch bei Google nach oben bekommen.
Wie erkennt Google Entitäten?
Die Unterscheidung zwischen benannten Entitäten und Konzepten ist entscheidend für die Erkennung von Entitäten. Benannte Entitäten können relativ einfach in Form von strukturierten und semistrukturierten Daten erkannt werden.
Strukturierte Daten
Die einfachste Art, Entitäten zu identifizieren, sind strukturierte Daten. Sie sind maschinenlesbar aufbereitet und können daher von Google leicht verarbeitet werden. Wenn du also strukturierte Daten auf deiner Website für SEO-Zwecke verwendest, gibst du Google auch Futter für die Erkennung von Entitäten.
Mit den strukturierten Daten werden viele Attribute geliefert, die Google helfen, eine Entität als solche zu erkennen:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Person",
"address": {
"@type": "PostalAddress",
"addressLocality": "Seattle",
"addressRegion": "WA",
"postalCode": "98052",
"streetAddress": "20341 Whitworth Institute 405 N. Whitworth"
},
"colleague": [
"http://www.xyz.edu/students/alicejones.html",
"http://www.xyz.edu/students/bobsmith.html"
],
"email": "mailto:jane-doe@xyz.edu",
"image": "janedoe.jpg",
"jobTitle": "Professor",
"name": "Jane Doe",
"telephone": "(425) 123-4567",
"url": "http://www.janedoe.com"
}
</script>Semistrukturierte Daten
Hierbei handelt es sich um Daten, die zwar nicht explizit maschinenlesbar aufbereitet sind, aber dennoch einer ausreichenden Strukturierung unterliegen, um von Google problemlos verarbeitet werden zu können.
Das bekannteste Beispiel für eine Website mit semistrukturierten Daten ist Wikipedia. Hier sind alle Artikel nach dem gleichen Prinzip aufgebaut und strukturiert. So weiß Google, dass eine H1-Überschrift in Wikipedia immer eine potentielle Entität ist.
Auch die Verlinkungen innerhalb der Wikipedia geben Google wichtige Hinweise auf Zusammenhänge und Verbindungen zwischen Entitäten.
Die gute Lesbarkeit ist neben der hohen Glaubwürdigkeit ein Grund, warum Google die Wikipedia häufig im Knowledge Panel anzeigt.
Unstrukturierte Daten
Google hört beim Entity Mining nicht bei Wikipedia und strukturierten Daten auf. Vielmehr arbeitet Google mit Natural Language Processing (NLP) daran, auch völlig unstrukturierte Daten für die Erkennung nutzen zu können.
Viele Google-Updates bzw. Technologien treiben das Thema NLP immer weiter voran:
- Hummingbird: dank dieser neuen Technologie war Google 2014 erstmals in der Lage Zusammenhänge zwischen Wörtern innerhalb einer Suchanfrage zu erkennen
- RankBrain (2015): Durch RankBrain ist Google in der Lage Entitäten aus Suchanfragen zu extrahieren und in den Suchergebnissen zu berücksichtigen. Beispielsweise die Location, damit wird Google auf den Weg gegeben, dass in einer Suchanfrage lokalisierte Suchergebnisse für eine bestimmte Entität (= dem Standort) ausgegeben werden sollen
- BERT (2019): verbesserte semantische Analyse der Suchanfragen
- MUM (2022): weiter verbessertes Verständnis der Suchanfragen. Laut Google 1000-mal leistungsfähiger als BERT und erkennen von Inhalten in Bild, Video und Text
Dank Natural Language Understanding ist Google in der Lage, die menschliche Sprache immer besser zu verstehen. So können Sätze in Subjekt, Objekt und Prädikat zerlegt und daraus semantische Informationen über die Entitäten gewonnen werden.
Die Natural Natural Language API demo zeigt, wie Google Sätze in ihre Bestandteile zerlegen kann:
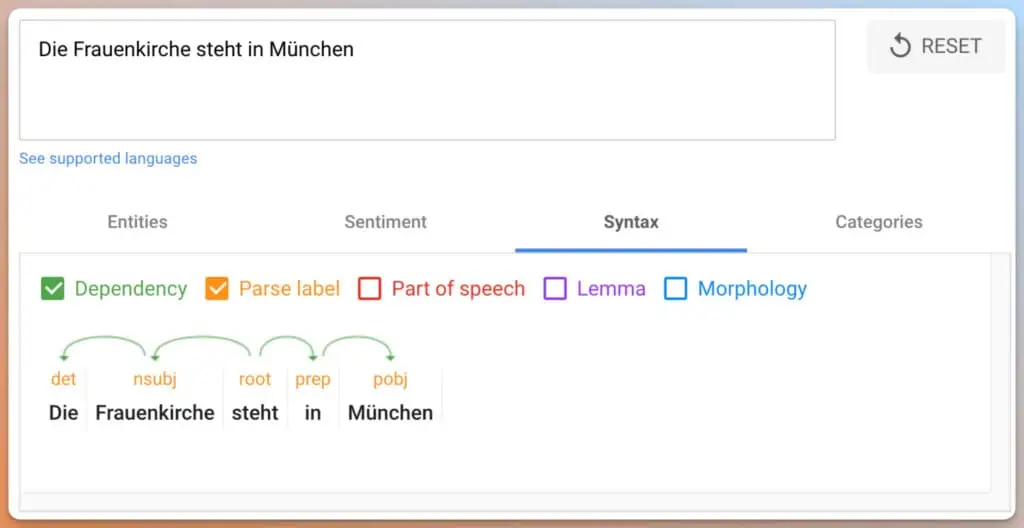
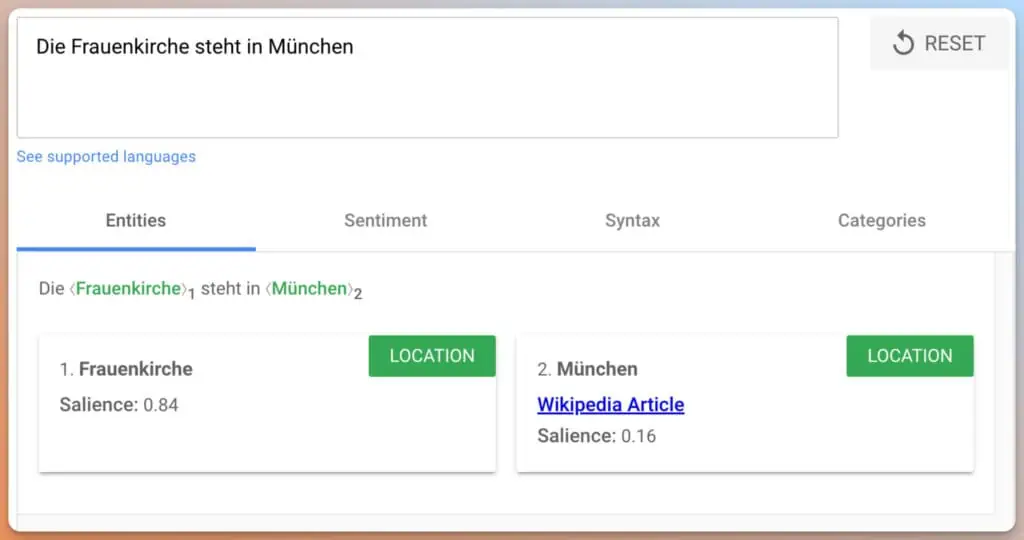
Anhand des Salience Score kann Google auch erkennen, wie wichtig ein Begriff innerhalb eines Satzes ist. Dementsprechend kann eine Entität im Vergleich zu anderen Entitäten innerhalb eines Satzes stärker gewichtet werden.
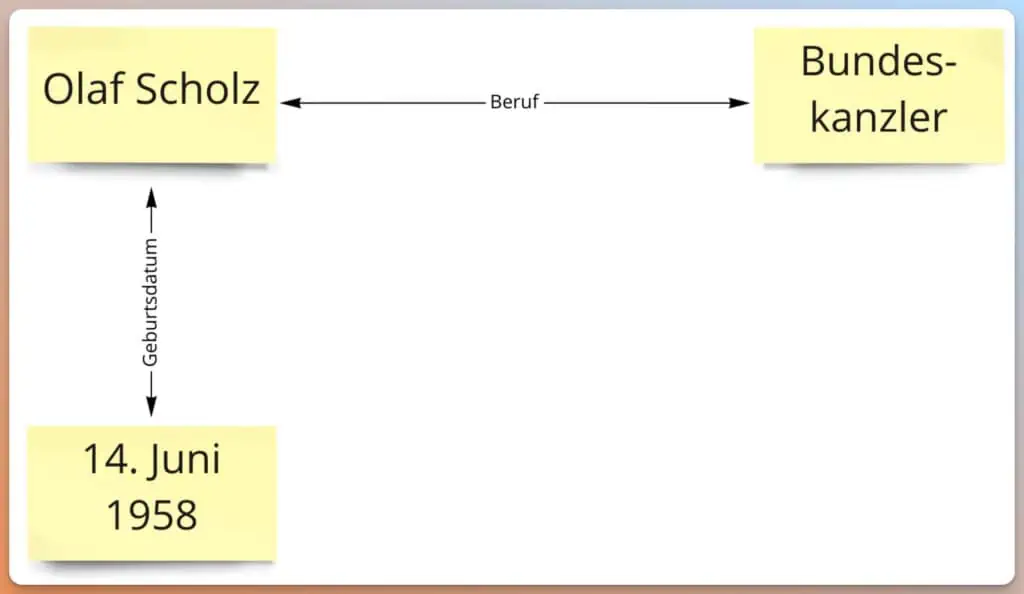
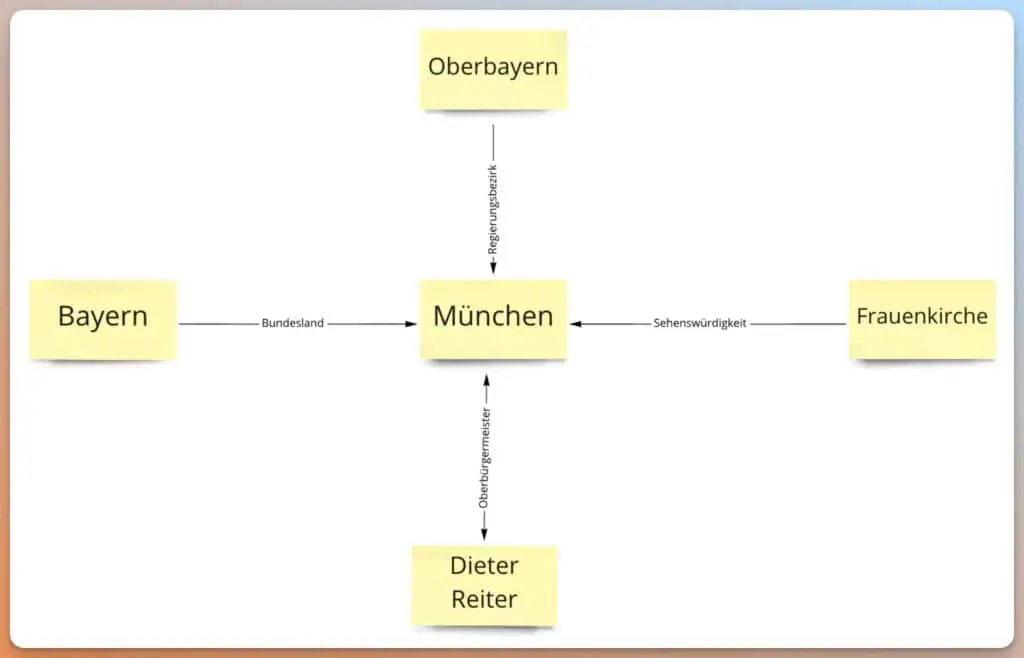
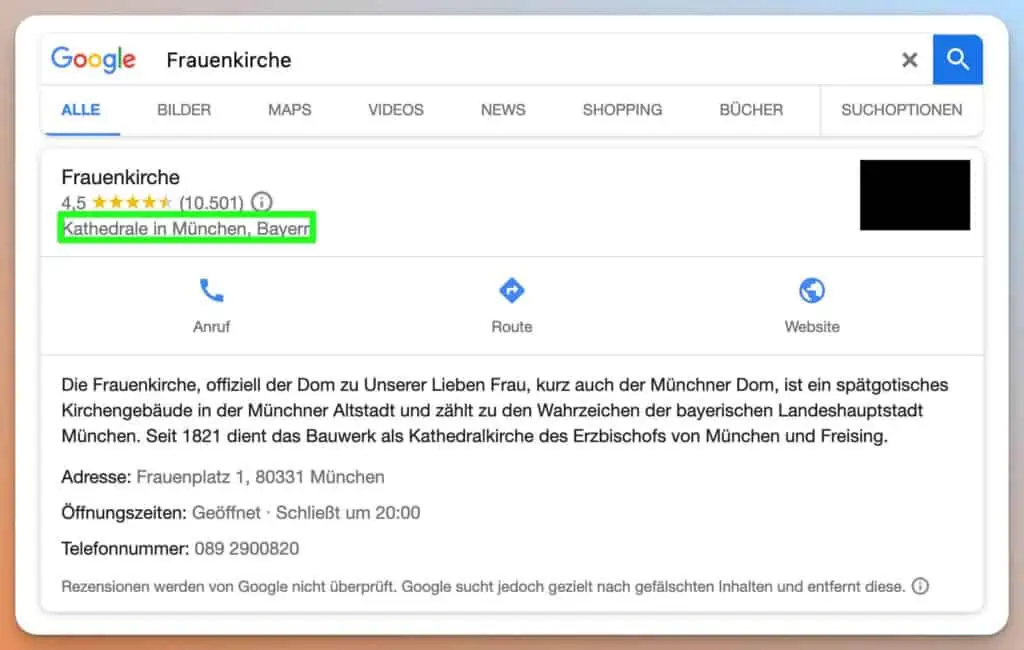
Gemäß dem Patent “Ranking search results based on entity metrics” kann Google lernen, wenn Entitäten miteinander in Beziehung stehen. Wenn zwei Entitäten häufig zusammen genannt werden, weiß Google, dass hier ein Zusammenhang besteht. Wie das Beispiel Frauenkirche und München zeigt.
Mit MUM ist Google in der Lage, Inhalte nicht nur aus Text, sondern auch aus Audio, Video und Bildern mit einer einzigen Technologie zu extrahieren, was bisher nur mit getrennten Anwendungen möglich war:
- Humming: Google erkennt Songs anhand der gesummten Melodie
- Lens: Google erkennt Objekte aus Fotos
- Multisearch: Google kombiniert Inhalte aus Fotos mit lokalen Suchergebnissen
All dies funktioniert nur, wenn Google das Gehörte (Humming) und das Gesehene (Lens) mit Entitäten verknüpfen kann.
Auf der Google I/O ‘22 wurde mit scene exploration eine weitere Entity-basierte Technologie vorgestellt: Inhalte von Fotos können mit Informationen aus dem Knowledge Graph kombiniert und durchsucht werden.
Als Beispiel wurde ein Regal mit Schokoladenprodukten fotografiert. Diese Produkte wurden mit Informationen aus dem Knowledge Graph abgeglichen. So konnte sich der Nutzer auf dem Foto nur die Produkte anzeigen lassen, die keine Nüsse enthielten, aus dunkler Schokolade waren und gute Bewertungen hatten:

Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Google muss nicht mehr Milliarden von Webseiten durchsuchen, sondern kann die Informationen direkt aus dem Knowledge Graph ziehen.
Die Frage “Was ist eine Entität” muss daher weiter gefasst werden. So müssen Eigenschaften von Entitäten nicht unbedingt in Textform vorliegen, sondern können auch Formen und akustische Elemente sein.
Die Verwendung von Entitäten geht also weit über die textliche Verwendung hinaus.
Was Entitäten für die Suchmaschinenoptimierung bedeuten
Die Möglichkeiten der Google-Suche bewegen sich immer weiter weg von Keywords, die in einen Suchschlitz eingegeben werden. Die List an Google Produkte, die ohne geschriebene Suchanfragen funktionieren wird immer länger:
- Discover
- Lens
- Humming
- Sprachsuche
Alle diese Produkte verwenden Entitäten. Wenn auch in unterschiedlicher Weise:
- Discover nutzt Entitäten, um vertrauenswürdige Publisher und Beziehungen zwischen Themen zu identifizieren.
- Lens nutzt den Knowledge Graphen, um die Texterkennung zu validieren (Quelle)
- Die Darstellung der Songs in Google Humming deutet auch auf Input aus dem Knowledge Graphen hin
- In der Sprachsuche werden häufig Fragen an Google gestellt, die Google direkt in Form einer Knowledge Card aus dem KG beantworten kann
Der Anteil der Suchanfragen, bei denen Google auf Entitäten angewiesen ist, nimmt also zu. Um darauf zu reagieren, sollten SEOs eine Strategie entwickeln, die der semantischen Suche gerecht wird:
- Identifizierung der für die eigene Website relevanten Entitäten. Diese müssen inhaltlich aufbereitet und miteinander verknüpft werden, damit Google die Zusammenhänge erkennt. Im Idealfall ist die Website selbst als Knowledge Graph aufgebaut.
- Nutze Tools wie die Natural Language API Demo, um ein Gefühl dafür zu bekommen, wie Google Entitäten aus Texten extrahiert.
- Schreibe klar und präzise, damit eine KI deinen Inhalt verstehen kann.
- Weniger in Keywords denken, sondern in Themen und Zusammenhängen
- Stelle die Absicht des Nutzers an die erste Stelle. Es gibt viele verschiedene Möglichkeiten, den gleichen Intent als Suchanfrage zu formulieren. Nutze deine Search Console Daten, um herauszufinden (z.B. mit einer N-Gram Analyse), was die User von deiner Website erwarten.
Fazit
Die Integration von Entitäten in SEO-Strategien läutet eine neue Ära der Suchmaschinenoptimierung ein, in der es nicht mehr nur um Keywords geht, sondern um die tiefere Verständlichkeit von Inhalten.
Google setzt zunehmend auf Entitäten, um die Nutzererfahrung zu verbessern, indem Inhalte nicht nur anhand von Schlüsselwörtern, sondern auch anhand ihrer Relevanz und ihrer Beziehung zum Kontext bewertet werden.
Für SEOs bedeutet dies, dass sie ihre Maßnahmen anpassen müssen: weniger Keyword-Fokus, sondern mehr Konzentration auf die Nutzerintention und hilfreiche Inhalte.
🔗 Weiterführende Links
An Introduction To Entities And SEO (Oncrawl 🇬🇧)
What Are Entities & Why They Matter for SEO (Search Engine Journal 🇬🇧)

Hol dir unser Wissen direkt in dein Postfach!
Einmal pro Woche schicken wir dir Wissenswertes rund um WordPress, SEO, KI, Datenschutz, Sicherheit, Texte, Bilder und Webdesign – verständlich aufbereitet, ergänzt um spannende Einblicke in den StrategieVier-Allltag. Trag dich direkt hier in unseren Newsletter ein!
Du meldest dich zu unserem Newsletter an. Macht vier Mal Website-Wissen pro Monat. Dafür nutzen wir Active Campaign. Du kannst dich jederzeit per Klick abmelden. Datenschutz.




